🎯 Project Objectives
During my Data Architectures course, I undertook a detailed study of Apache Cassandra with a brilliant friend and classmate. The objective was to evaluate Cassandra's architecture and performance, and benchmark it against other popular databases like PostgreSQL and MongoDB.
🔍 Key Areas of Focus
We focused on understanding the fundamental components of Cassandra, such as its storage mechanisms (commit log, memtables, SSTables), compaction process, and replication strategies. We also studied Cassandra's approach to handling distributed data and ensuring fault tolerance through features like the gossip protocol and tunable consistency levels.
For benchmarking, we used the Cassandra-Stress tool to simulate various workloads and measure performance in different scenarios, including node failures and varying consistency settings. The comparison with other databases was based on criteria such as read/write performance, scalability, and fault tolerance.
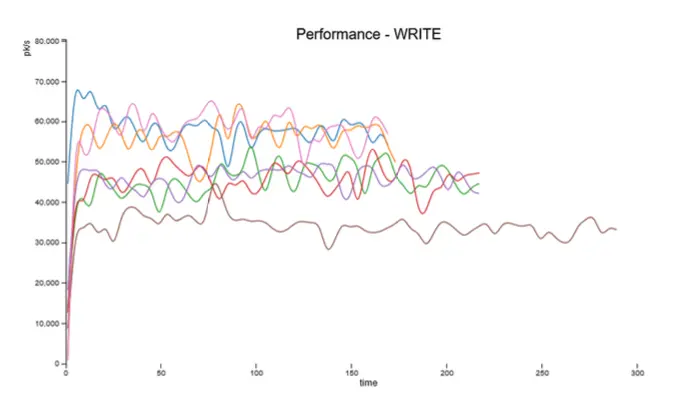
🛠️ Work Done
We began by setting up a Cassandra cluster using Docker containers, ensuring we could simulate a production-like environment. Our setup included multiple nodes to test Cassandra's scalability and fault tolerance features. We configured various replication strategies and consistency levels to observe their impact on performance.
Using the Cassandra-Stress tool, we conducted a series of benchmarks focusing on both write and read operations. We tested different scenarios, including:
- Write-heavy workloads: Evaluating Cassandra's performance in handling a high volume of write operations.
- Read-heavy workloads: Assessing how well Cassandra manages read operations compared to other databases.
- Mixed workloads: Combining read and write operations to simulate real-world applications.
- Failure scenarios: Simulating node failures to test Cassandra's fault tolerance and data consistency mechanisms.
Our analysis extended to comparing these results with PostgreSQL and MongoDB, particularly focusing on how Cassandra handles large-scale distributed data and ensures high availability.
📈 Insights Gained
Through this project, we developed a solid understanding of how Cassandra's architecture supports high scalability and availability. The benchmarks demonstrated Cassandra's strength in write operations and fault tolerance, although it showed varying performance in read-heavy tasks compared to SQL databases.
One of the key takeaways was the impact of Cassandra's tunable consistency on performance. By adjusting the consistency levels, it is possible to balance between high availability and data accuracy, making Cassandra adaptable to different application needs.
❤️ Project Highlights
This project was a fascinating exploration into the world of NoSQL databases. I thoroughly enjoyed the hands-on experience of setting up and testing Cassandra clusters, and the challenges of benchmarking its performance under different conditions. Working closely with my friend made the process even more enriching, as we collaborated and learned together.
Our dedication and curiosity to push the boundaries paid off. We went the extra mile by running extensive Cassandra clusters to benchmark its performance comprehensively. The teacher was highly impressed with our work, and we received the highest grade for our excellence. This recognition was a testament to our hard work and passion for exploring new technologies. Achieving top grades and making the teacher proud was a great recognition of our efforts! 😎